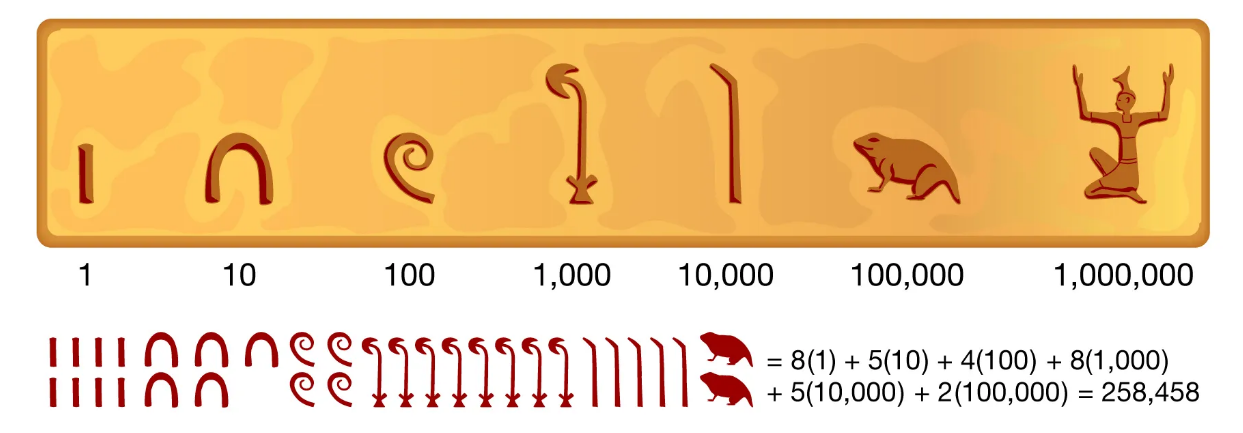
上次我们对第20届语言学奥林匹克竞赛(IOL)个人赛的第5题,也就是数字题进行了分析和解答【1】,今天来试一试第4题,这是一道文字题。

一般来说和数字题相比,文字题要更复杂一些,涉及语言学的要素也会更多一些。这道文字题的语言背景是平原克里语,这是个啥语言、什么人用的语言我们并不关心;我们关心的是如何利用示例来建立起逻辑自洽的语言结构。
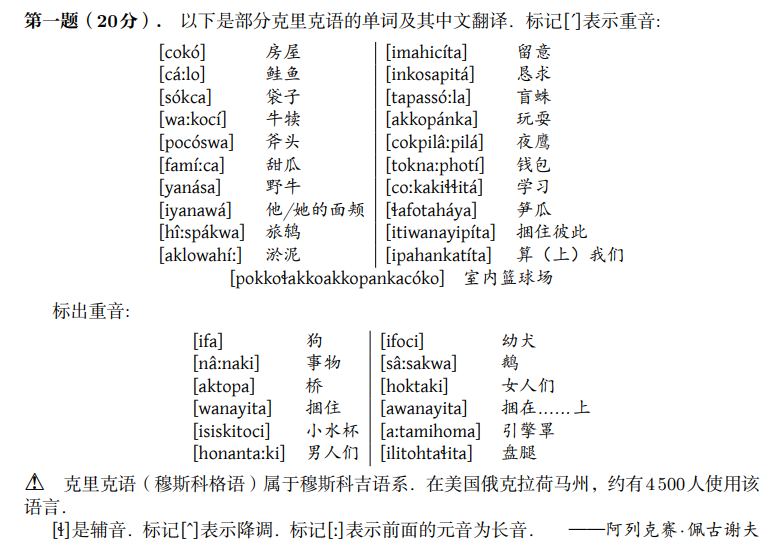
题目中给出了21个示例,其中16个例子在汉语中都是“人称代词+动词+人称代词”的结构,另外给出了5个示例,分别对应于从句“当……时”和“如果……”。题目的任务是(a)将四个平原克里语短句翻译成汉语,和(b)将五个汉语短句翻译成平原克里语。
我们先粗略地对前16个示例的汉语翻译做一个统计,分别统计短句中的动词和人称代词。
动词方面,16个示例中一共出现了5个动词,这5个动词及其出现的示例数如下:
1. 挑战,出现3次。
2. 看到,出现4次。
3. 阻止,出现3次。
4. 问,出现3次。
5. 帮助,出现3次。
对于每个动词,在它的示例中找出“最大公约数”,即最大的相同部分。比如对比示例5,13和16,找出wīcih是这三个短句的最大的相同部分。
注意:这个部分不一定就和动词的原型一一对应——因为还可能有性、数、格的不同——但至少包含了动词的词根。
1. 挑战 = mawinēskom。
2. 看到 = wāpam。
3. 阻止 = nakin。
4. 问 = kakwēcim。
5. 帮助 = wīcih。
我们注意到后面5个动词的相同部分最后都以辅音结束,所以为了保持一致,我们省去第1个动词相同部分的最后一个元音字母i。
再来看看人称代词部分。从汉语翻译中,我们可知人称代词在这些示例中以主语或者宾语两个语法成分出现,再加上第一、第二和第三人称的单复数,组合起来一共有36种可能。
我们将这些可能用下表来表示,其中行标题表示主语,列标题表示宾语,表格中的数字是示例的编号:
| 主语\宾语 | 我 | 我们 | 你 | 你们 | 他 | 他们 |
| 我 | – | – | 16 | 21 | 7,18 | 12 |
| 我们 | – | – | 11 | 11 | 6 | 4 |
| 你 | 8 | 3 | – | – | 5,20 | ? |
| 你们 | 2 | 3 | – | – | 17 | 15 |
| 他 | 1 | ? | 10 | 13 | – | – |
| 他们 | 19 | 9 | 14 | ? | – | – |
可见,示例并没有完全涵盖这36种可能,其中反身用法(如:“我……我们”,“你们……你”,“他……他”等)没有在示例中出现,也没有在任务(b)中出现,所以我们在以下的分析中忽略这12种可能。
注意到,这里有两个特殊的示例:3和11。对应的汉语翻译中,这两个短句可以翻译成“你”,也可以翻译成“你们”。但在另外一些示例,比如8和2,分别只能翻译成“你”或者“你们”。这是一个需要注意的点。
除去这些种可能,另外还有3种可能的组合没有在示例中出现,我们将它们用“?”表示。注意到,部分组合出现在任务(b)中,比如任务30就是“我……你们”的组合。不排除在任务(a)中也出现部分缺失的组合。
我们发现在示例中动词的相同部分相对统一和简单,所以将它们从短句里拆分出来,我们把分析的重点放在人称代词上。
下一步,我们把分析的重点放在人称代词上,这是因为我们发现动词在示例中出现的形式比较统一,相对简单。所以我们将动词相同的部分从短句中拆分出来:
1. ni – ik — 他挑战我
2. ki – ināwāw — 你们看到我
3. ki – inān — 你阻止我们,你们阻止我们
4. ni – ānānak — 我们问他们
5. ki – āw — 你帮助他
6. ni – ānān — 我们问他
7. ni – āw — 我看到他
8. ki – in — 你挑战我
9. ni – ikonānak — 他们挑战我们
10. ki – ik — 他问你
11. ki – itinān — 我们看到你,我们看到你们
12. ni – āwak — 我阻止他们
13. ki – ikowāw — 他帮助你们
14. ki – ikwak — 他们阻止你
15. ki – āwāwak — 你们看到他们
16. ki – itin — 我帮助你
我们用同样的方式处理示例17 – 21:
17. ē- – āyēk — 当你们阻止他时
18. ē- – ak — 当我帮助他时
19. – ikoyāhkwāwi — 如果他们挑战我们
20. – aci — 如果你看到他
21. – itako — 如果我帮助你们
把动词拆出来后,我们很容易发现:
1. 前16个短句要么以ni-开头,要么以ki-开头,而且两种类型似乎和第几人称无关,因为示例中包含了各种人称。
2. “当……时”的从句应该和ē- 相对应。
3. “如果……”的从句直接以动词开头。
个人感觉ni-和ki-的区别是解决本题的关键。
分析示例4,6,7和12,即人称代词表格中右上角的四个方格,它们表示主语为第一人称、宾语为第三人称的四种情况,我们发现在平原克里语中这四个示例全以ni-开头,所以初步猜测ni-和第二人称没有关系。
为了进一步确认这一猜想,我们再看看示例1和9,即人称代词表格中左下角的四个方格,它们表示主语为第三人称、宾语为第一人称的两种情况,这两个示例确实全以ni-开头。而以上这6个示例恰恰是16个示例中和第二人称无关的所有示例!
那么反过来,ki-开头的短句是否全部都与第二人称有关呢?我们查验以下另外10个以ki-开头的示例,确实都与第二人称有关!
因此,我们可以推断出:ni = 主语和宾语仅和第一人称、第三人称有关;而ki = 主语或宾语与第二人称有关。
得到这个推断的同时,我们也意识到动词前面的ni-或者ki-并不代表某个特定的人称,这意味着不论是主语还是宾语,它们都位于动词后面。所以我们下面把重点放在动词后的那一堆字母之上。
回到表格的右上角,这4个示例是第一人称作为主语、第三人称作为宾语时的情况:
7. ni – āw — 我看到他 vs. 12. ni – āwak — 我阻止他们
6. ni – ānān — 我们问他 vs. 4. ni – ānānak — 我们问他们
比较这四个短句动词后的部分,从7和12,6和4可以推测出-ak后缀表示第三人称复数,从7和6可以推测出-nān后缀表示第一人称复数。其中示例6中表示第三人称单数-w可能因为缺少元音而被省去。
小结一下:
“我……他” = āw;“我……他们” = āw-ak;
“我们……他” = ā-nān;“我们……他们” = ā-nān-ak。
这个推测在示例18上可以得到验证。
再来看左下角的两个示例。
1. ni – ik — 他挑战我
9. ni – ikonānak — 他们挑战我们
对比一下,可以猜测-ik表示“他……我”,-iko表示主语的“他们”,而这里出现的-nān表示“我们”,-ak表示“他们”,符合我们上面的推测。
将示例9和示例4进行比较,可见iko的作用就是表示第三人称成为主语。
小结一下:
“他……我” = ik;“他们……我们” = iko-nān-ak。
不过,虽然示例19符合-iko的用法,但其它部分非常复杂,条件从句的情况我们留到后面再讨论。
再来看看和第二人称有关的ki-句式。
示例16和11表示第一人称主语、第二人称宾语的情况:
16. ki – itin — 我帮助你 vs. 11. ki – itinān — 我们看到你,我们看到你们
可知-itin表示“我……你”,-iti-nān表示“我们……你”,这里-nān的后缀用法也符合我们上面的推测。
示例21也是条件从句,留在后面讨论。
示例10,13和14表示第三人称主语、第二人称宾语的情况:
10. ki – ik — 他问你 vs. 13. ki – ikowāw — 他帮助你们
14. ki – ikwak — 他们阻止你
很有意思,这里表示“他……你”的也是-ik,和“他……我”一样。那么怎么区分宾语到底是“你”还是“我”?很简单,看句子是ni-还是ki-开头。
示例13中,-iko表示第三人称作主语,符合我们上面的推测,剩下的-wāw表示第二人称复数。
示例14中,-ak表示第三人称复数,ik和ak之间用w连接。
再来看看第二人称作主语的情况。
示例8,2和3表示第二人称主语、第一人称宾语的情况。
8. ki – in — 你挑战我
2. ki – ināwāw — 你们看到我 vs. 3. ki – inān — 你阻止我们,你们阻止我们
上面例子说明-in表示“你……我”,和表示“他……我”或者“我……他”的-ik同样简洁。
表示“你们……我”的-ināwāw中,-in表示第二人称作主语,-(ā)wāw表示第二人称复数。
表示“你……我们”的-inān类似于in-nān,符合我们上面的推测,两个连续的n可能被省去了一个。注意到,在有第一人称复数-nān的情况下,在平原克里语法上可能无法再加上-wāw表示第二人称复数,所以示例3和11中,对于第二人称都存在单数和复数两种不同的解读。
示例5和15表示第二人称主语、第三人称宾语的情况。
5. ki – āw — 你帮助他
15. ki – āwāwak — 你们看到他们
-(ā)wāw表示第二人称复数,-ak表示第三人称单数,再次验证了我们上面的判断!
示例17表示了“你们……他”的情况。
17. ē- – āyēk — 当你们阻止他时
这个不大好分析。因为缺少了ni-和ki-带来的额外信息,我们不知道哪个部分指定了第二人称,从示例1、5、7可以看出,第三人称单数作为宾语大致是默认的。所以可以猜也许整个-āyēk就是表示“你们”作主语。
最后看看3个和条件从句有关的示例19,20和21。我只能分析出部分的语法结构:
19. – ikoyāhkwāwi — 如果他们挑战我们
这里-iko表示第三人称为主语,后面一堆yāhkwāwi不知道如何拆,只知道它表示“他们……我们”。
20. – aci — 如果你看到他
这里-aci也没法拆,在以ki-开始的普通句式中,“你……他”用-āw来表示,但在这个条件从句中,看不出两者之间的联系。
21. – itako — 如果我帮助你们
这里能看出来的只有-it,表示第一人称主语、第二人称宾语。那么-ako就和第二人称复数有关。在以ki-开始的普通句式中,第二人称复数用-(ā)wāw来表示,同样看不出两者之间的联系。
最后,让我们来尝试完成任务。
(a)
22. ē-wāpamikoyēk = ē-wāpam-iko-yēk。ē-表示“当……时”,wāpam表示动词“看到”,iko表示第三人称为主语,参考示例17,yēk应该表示的是“你们”,所以这个短句翻译为:当他看到你们时。
23. ninakinikonān = ni-nakin-iko-nān。ni表示与第二人称无关的内容,nakin表示动词“阻止”,iko表示第三人称为主语,nān表示第一人称复数,参考示例9,所以这个短句翻译为:他阻止我们。
24. kikakwēcimāwāw = ki-kakwēcim-āwāw。ki表示与第二人称有关的内容,kakwēcim表示动词“问”,-(ā)wāw表示第二人称复数,默认第三人称单数,参考示例15,所以这个短句翻译为:你们问他。
25. kiwīcihitināwāw = ki-wīcih-itin-āwāw。ki表示与第二人称有关的内容,wīcih表示动词“帮助”,itin表示“我……你”,-(ā)wāw表示第二人称复数,所以这个短句翻译为:我帮助你们。
(b)
26. 如果我们问他们。“如果……”是条件从句,动词“问”是kakwēcim,第一人称和第三人称都是复数,参考示例19,不过这里“我们”是主语,示例19中“我们”是宾语,因为iko表示第三人称作主语,将iko换成a表示第一人称作主语,所以这个短句翻译为:kakwēcim-a-yāhkwāwi。
27. 他们挑战你们。和第二人称有关用ki开头,动词“挑战”是mawinēskom,第三人称复数作主语用iko-…-ak,第二人称复数用-(ā)wāw,参考示例13和14,且示例中从未出现连续两个元音,所以这个短句翻译为:ki-mawinēskom-iko-wāw-ak。
28. 他们帮助我。和第二人称无关用ni开头,动词“帮助”是wīcih,“他们”作为主语是iko-…-ak,参考示例14,所以这个短句翻译为:ni-wīcih-ik-w-ak。
29. 你看到他们。和第二人称有关用ki开头,动词“看到”是wāpam,第三人称复数作宾语用āw-ak,参考示例5,所以这个短句翻译为:ki-wāpam-āw-ak。
30. 我阻止你们。和第二人称有关用ki开头,动词“阻止”是nakin,第一人称作主语、第二人称作宾语为itin,第二人称复数用-(ā)wāw,参考示例16和2,所以这个短句翻译为:ki-nakin-itin-āwāw。
参考出处: